工作內容
摘要
隨著網際網路的發達,現代人的消費型態逐漸從實體商店轉為網路商店,根據中華民國經濟部統計處調查,台灣電子購物業營業額從民國100年之1103億元,攀升至民國106年之1695億元,其中衣服及服飾配件業占16.0%。為了搶佔如此龐大的商機,業者紛紛推出線上試衣功能試圖吸引消費者注意。
但目前線上試衣或是透過行動APP試衣的軟體,具有一項很大的限制,就是必須透過其他設備擁有人體數據才有辦法進行線上試衣。
本研究為了實現隨時隨地都能使用本研究中的功能,採用以單張影像實現虛擬試衣間功能,並以YOLOv3偵測人體位置製作初步mask改善GrabCut運算效率,運用OpenPose標定出人體關節點位置,使得衣服貼合位置更精確,並且以肩寬估計出側身角度,使衣服能更切合人體原先姿態。
考量購買衣服的動機並非只有為自己購買,還可能是情侶間的情侶裝或是親子間的親子裝,因此本研究不僅支援單人著裝,亦支援多人著裝。
1.前言
近年來,消費者的消費型態逐漸從實體商店轉為網路商店 [1],虛擬試衣間成了一項提升消費者購買意願的工具,但線上試衣卻苦於收集人體數據時仍須有特定設備,並不能算是完全的線上試衣,同時,基於行動裝置照相技術的改進,與社群媒體的興起,帶動了大眾隨時隨地照相的風氣,但大量的照片卻並沒有好的應用方向,基於以上兩種因素,我試圖結合兩者,創造出一種具備價值的應用,因此開發出依據單張影像實現虛擬試衣間的功能,讓消費者可以隨時隨地,無時無刻的體驗試衣,不被設備所侷限。
2.文獻探討
有關虛擬試衣間的研究,部分偏向使用多部攝影機採集深度訊息[2],或是使用紅外線探測深度[3],也有一部分先對使用者進行3D掃描採集人體數據[4],這幾種方式雖然具有相當的精準度,但或礙於設備,或礙於使用者周遭環境,並不是無時無刻都能使用,缺乏即時性。於2.1節我們探討三篇虛擬試衣間相關研究與一個實際案例,並分析利弊。
此外,對於本研究所需之相關技術,於2.2節介紹前後景分離,於2.3節介紹人體檢測定位,於2.4節介紹關節點檢測定位,並對這幾種技術分析相關利弊,解說本研究採取該技術之相關原因。
2.1虛擬試衣間相關研究
Dimitris Protopsaltou等人[2]提出了運用了現實衣服尺寸的規格,同時引用日內瓦大學相關引擎模擬現實物理參數的技術,在配戴相關感應設備的情況下,由多部攝影機收集數據,最後利用相關數據進行對應處理。雖然擁有很精準的效果,但需要有多台攝影機收集數據,同時須計算衣襬垂落等物理特性,未能達到即時性的效果。
Ya-Yun Chen提出有關二維線上虛擬試衣間之研究與開發[3],該論文提出以Kinect作為輔助工具,做出半自動去背,但此種方法有設備上的限制,無法達到隨時隨地都能使用,同時Kinect對於被遮擋的目標感測效果不好,且Kinect目前已停產,對於後續開發利用,著實不便。
Scott William Curry等人提出[4]以3D掃描取得使用者的身體數據,配合已知的物理與材料特性,為使用者套上衣服,優點是看起來真實,但缺點是需要先經過3D掃描才能做後續的處理,有著設備與地點上的限制。
Style.me是一個主打3D虛擬線上試衣間的網站[5],他們需要使用者提供身高、體重、三圍作為他們虛擬模特兒的體態模擬數據,不需要額外設備,也能做到3D試衣的功能,但缺點是使用者需要自己輸入身高、體重、三圍,使得使用者需要先測量好自己的相關數據,才能進行試衣,不夠自動化。
2.2前後景分離
為了讓使用者能針對不同的背景進行不同的搭配,因此必須將使用者從原先影像的背景中提取出來。要將影像從原先背景提出就需要用到前後景分離的技術,其中最知名的就是GrabCut[6]。
GrabCut是基於GraphCut[7]所研究出來的技術,與它的前身不同,GrabCut目標背景模型採用RGB三通道混合高斯模型(Gaussian mixture model,在此簡稱GMM),在每個像素中,計算RGB的GMM權重、GMM的均值向量,以及GMM協方差矩陣,歸類為前景權重或是背景權重,最後依此判斷出前後景的邊線。對於處理高解析度圖片耗時長是一大問題,同時對於複雜背景或是顏色相近前後景處理成果也不佳。GrabCut中有使用border matting[8]的技術對邊緣進行平滑化,但因具有專利問題,本研究中不使用這項技術。
2.3人體檢測
電腦並不能像人類一樣識別影像中具有何種物體,對於電腦來說,影像就只是像素集合而成的像素點矩陣,因此想要將人體從影像中提取出來,必須先檢測出人體位置的範圍才行,為了試衣間運行的速度,我們採用號稱最快速做到影像辨識的機器學習框架YOLO[9]。
YOLO透過對整張影像切分成S×S大小的格子,對每個格子進行預測,如此省去了每次預測不同物體重新卷積整張圖像的時間。在本研究中結合YOLO的速度特點,將判定為人體的方格設定為前景權重,其餘設定為背景權重,即可在第一次尋找範圍時,節省大量的運算時間。
2.4關節點檢測
在2.3節中我們提到使用YOLO找出人體位置的技術,但是YOLO找出的框在每個人身上套的不會是同一個位置,無法因此推斷衣服貼合的位置,因此我們需要檢測關節點,來確定衣服貼合位置,OpenPose[10][11]就是一項關節點檢測的相關技術。
Shih-En Wei等人提出關節點的檢測,需要其他關節點的提示,因此擴大了卷積網路的感受野[10]。經過實測,在正面的狀況下,幾乎可以達到完美的效果,但在側面的狀況下,容易因為衣服不同而導致判斷錯誤,如外套分兩側,會只將關節點判斷在其中一側。
隔年,Shih-En Wei等人提出[11]改善[10]所提及的關鍵點檢測問題,透過匈牙利算法的技術,對合適的兩關節進行相連,權重分配用到了他們的相關性。
3.研究方法
3.1研究限制
本研究所實驗之服飾為2D圖像照片,不包含3D服裝,因此對於側面(轉身90度)及背面(轉身180度)不做處理。同時,使用者拍照姿勢各式各樣,無法完全精準模擬,因此只針對雙手自然垂放且直立的人體進行處理,舉凡彎腰或舉手或蹲下等情況則不另做處理。
3.2使用環境
使用工具:OpenCV:3.4.0[12]負責處理4.3節衣服大小調整、衣服變形處理,OpenPose:1.3.0[10][11]負責處理關節點檢測,YOLO:YOLOV3[9]負責處理人物位置檢測,作業系統:Microsoft Windows10,硬體配置:CPU:i7-7700 RAM:12GB
3.3功能架構
圖1為本研究系統之功能流程圖,以下解釋研究系統功能架構之運作方法。
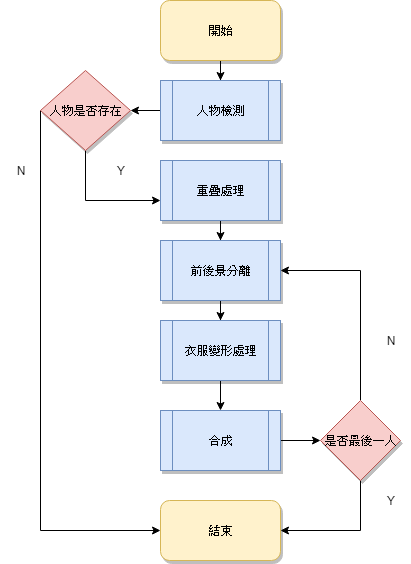
圖 1 功能流程圖
首先,在開始的部分,使用者需要先選擇想更換的衣服以及想替換的背景,選擇完畢後,系統進入人物檢測的部分。
在人物檢測的部分,進行以下三步驟的處理
1. 以YOLO計算人物中的位置,並回傳座標
2. 以OpenPose計算人物中的關節位置,並回傳座標。
3. 比對YOLO回傳之人物座標與OpenPose回傳之關節座標,若人物座標包含所有關節座標,則此人存在,其餘皆視為不存在。
若人物存在,即進行下一部份,重疊處理,若不存在,則直接結束程式。
重疊處理的部分,首先區分為單人及多人。依據人物檢測傳遞之人物座標數量,可以判斷此圖為單人抑或多人。若判斷為單人,則直接進入前後景分離,若為多人,則需以不同情況進行重疊處理。重疊情況我分為3種,完全重疊,左右重疊,以及上下重疊。3種情況分別做以下處理:
1. 完全重疊:例如親子合照,為了全部人能入鏡,則小孩(體型小)會在大人(體型大)前方,因此圖層順序以體型小在前,體型大在後。
2. 左右重疊:這部分並不容易判斷,因具有體型問題,容易有誤判情況。但在此,我假定重疊兩人體型相差不大,則根據人物距離鏡頭的遠近,可以判斷出距離鏡頭近的體型看起來較大,距離鏡頭遠的體型看起來較小,因此圖層順序以體型大在前,體型小在後。
3. 上下重疊:在這部分就不容易出現誤判的情形,因照相時,無論是因距離鏡頭較遠而在圖片偏上的位置,或是體型大而在圖片偏上的位置,都會是在後方,因此圖層順序以位於圖片下方在前,圖片上方在後。
詳細處理判斷見4.1節。處理完重疊部分的圖層判斷後,便進入前後景分離的部分。
前後景分離的部分,一次以一人做處理。對於原先純粹使用GrabCut會對整張圖片做處理,容易被特徵明顯,如遠處金屬光澤所干擾,我在此部分有所改進,我利用人物檢測部分檢測到的人物座標製作GrabCut的初步mask。此mask製作方法如下,先將YOLO判斷為人標籤的方格設定為前景,其餘在邊界外方格設為背景,如此可以加快GrabCut判斷前景背景的速度。再以製作出的mask進行GrabCut的運算,最後成功分離出前景及背景。前後景分離處理完畢後,程序進入衣服變形處理的部分。
衣服變形處理,我分為兩個步驟去執行。
1. 調整衣服大小:在這一步驟中,因為使用者上傳的圖片像素大小不同,人物佔全圖比例也不同,用同樣大小衣服直接貼合顯然是不對的,因此我依據肩寬去調整衣服大小,使衣服能完美貼合使用者身形,調整衣服大小我採用雙線性插值[13],因為調整後的衣服大小並不一定是整數,無法完整落於像素點上,因此需要使用雙線性插值對小數點進行調整,使紋理呈現更平滑。
2. 計算雙肩傾斜程度:人體或是因為站姿,或是因為側身,雙肩很少會達到水平的狀態。在此,我先以肩寬與身長的比例來判斷雙肩傾斜是因為站姿或是側身。判斷標準見4.3節。若是站姿問題,則調整衣服雙肩位置以符合使用者肩線。若是側身問題,則以雙肩高度差作依據,在肩膀較高一側上下各加雙肩高度差,如圖2所示,矩形a為未側身前衣服圖片,橙色梯形為側身後衣服圖片,矩形b為依據肩寬調整後之衣服圖片,三角形則為雙肩高度差形成之面積,在未能得知未側身前之衣服大小的情況下,我們以上方加入雙肩高度差,同時下方加入雙肩高度差,即可形成側身後的效果,同時因雙肩肩寬是側身後所測量,因此能呈現出側身後大小,看起來較為真實。計算衣服傾斜角度:人體在影像中可能因為拍照姿勢的不同造成下半身與上半身並非鉛直的狀態,因此我依據髖骨座標與肩膀座標的對應,計算衣服傾斜的角度,使得衣服肩膀能對到肩線,衣服下襬部分也能對齊兩側髖骨。
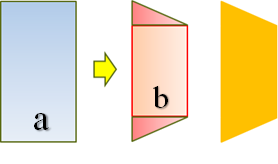
圖 2 側身轉換示意圖
處理完衣服的變形部分後,就進入合成的階段。
在合成的階段,我首先先將前後景分離部分分離出的前景合成到使用者挑選的新背景上,再將衣服合成到人物上。合成完畢後,判斷現在合成的人物是否是人物檢測部分所判斷的最後一個人,若是最後一個人,則程序結束,若否,則進入下一個人的前後景分離程序,直到執行到最後一個人為止。
4.實驗過程
4.1重疊判斷
應付多人檢測的狀況下,不可避免的,我們會遇到人與人之間相互遮擋的重疊問題。大致上,我們可以把人與人之間的重疊問題,分成完全重疊與部分重疊。
完全重疊的部分,見圖3(左),如大人與小孩,基於不被遮擋的狀況下,可檢測出有兩個人,判斷前後順序可判斷出體型小者(小孩)會在前,體型大(大人)會在後,才不會出現檢測不到體型小(小孩)的問題。
部分重疊的部分,又能細分為左右重疊及上下重疊。左右重疊的狀況,見圖3(中),一樣以體型作為區分,越靠近鏡頭的人體,理應體型越大,因此體型較小者會距離鏡頭較遠,如遇到體型較嬌小者雖靠近鏡頭較近,卻無法明顯區分出與遠離鏡頭但體型高大者的區別時,將與上下重疊的方法進行結合。上下重疊的狀況,見圖3(右),我們可以很明顯地得到腳距離影像最下方越遠時,具離鏡頭越遠。撇開為了拍出浮空照片等特殊情況,人體拍照時,腳會與地面貼合,同時現實中的地平線對於照片中每個人會是相等的,依據消失點的理論[14],我們可以得知,為了將3D畫面呈現在2D屏幕上,地平線會往消失點匯聚,造成人站的位置不一樣高,因此可以以腳的位置推斷出前後順序,如遇到拍照缺失腳的情況下,則以此類推,往上找其他關節當作基準點,進行對照。
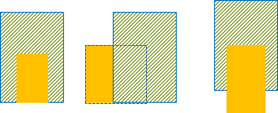
圖 3 示意圖(左)完全重疊,(中)左右重疊,(右)上下重疊
4.2前後景分離
針對前後景分離的部分,使用Graz數據集[15]進行實驗,透過實驗,大小為480x640像素圖片,人物佔全圖比例大(90%),約莫需要9.093秒(計時單位採時脈計算,以下皆同),對於使用者來說,速度太慢了,因此我結合YOLO標定人體位置的方式,初步製作GrabCut的mask,再利用此mask對圖片進行運算,最後得出結果約為4.686秒,節省了將近一半的時間,同時也得到較佳的分離結果。同時,我也對人物相對全圖比例小(15%)進行實驗,不使用YOLO製作mask需要耗費13.092秒,而使用YOLO製作mask加起來總秒數卻只花3.052秒,時間消耗只有四分之一,結論見表1。人物比例佔全圖越小,使用GrabCut處理全圖耗費時間越長,而使用YOLO製作mask人物佔全圖比例越小,則節省時間越多。在此節,使用之YOLO權重為YOLOv3 weight[9]分類器為COCO dataset[16]。
表 1 前後景分離對比結果
| 使用方式 | GrabCut處理全圖 | YOLO決定初步位置+GrabCut處理 |
| 佔全圖比例大(90%) 時間(s) |
9.093 | 1.698+2.988 |
| 佔全圖比例小(15%) 時間(s) |
13.092 | 1.666+1.386 |
4.3衣服變形處理
1. 衣服肩線校正
依據論文[17]採樣,人體在自然放鬆的狀況下,踝關節等身體關節會隨著外在環境影響或疲累等自主切換關節角度,導致站姿不會左右相等。對於此種狀況,我計算左右肩膀高度差,如果測量高度差座標小於1,那就當作誤差無視,如果高度差座標大於等於1,則依據肩膀高度差進行換算衣服變形。原圖見圖4(左),圖4(中)為使用OpenPose檢測之關節結果,可見檢測出之雙肩位置非水平,圖4(右)對衣服做相關變換後,使衣服符合雙肩位置,對到肩線。

圖 4 (左)原圖[15],(中)檢測關節,(右)衣服校正結果,衣服[18]
2. 透視變換
人體側身對於人類來說,十分容易辨別,因為人類能以雙眼交疊的影像形成深度,進而判斷出人體現在是側身。對於計算機視覺來說,側身與正面並沒有不同,兩者均有X軸,Y軸訊息,同時缺失深度訊息,因此讓電腦利用2D影像模擬出3D訊息著實困難。
在此,我假設正面肩寬與身長的比例約為0.6:1,經數據集挑選出之正面圖片驗證後,無一例外,因此在此可得出肩寬約為身長的0.6倍。但因照片俯仰角度有可能會造成計算誤差,因此我放寬0.1的標準,以肩寬為身長0.5倍作為基準,判斷照片中人體是否側身。
假設人體是側身的狀況下,人體的肩線與兩側髖骨間的連線會匯聚在一個點,稱為消失點。在關節點檢測的結果中,我們看不出兩側髖骨的高度差關係,但卻可以明確看出雙肩的高度差,因此我以雙肩高度差取得消失點上方斜率,再於肩膀較高一側之髖骨位置做相反斜率,最終這兩條斜率會於消失點匯聚。以此兩條線作透視變換,便能成功得到衣服的傾斜角度及紋理。圖5(左)為原圖,可很明顯看出肩膀往圖片右側傾斜;圖5(中)為未進行透視變換直接進行貼圖,雖然能直接遮蓋住衣服的部分,但無法貼合肩線;圖5(右)為進行透視變換後進行貼圖,可以看出衣服已經貼合肩線,但因無光影變化,難以看出傾斜的深度。

圖 5 (左)原圖[15],(中)透視變換前,(右)透視變換後,衣服[19]
3. 關節點檢測修正
以OpenPose對人體進行關節點檢測,大部分狀況下,都能得到不錯的結果,但是對於分開成兩側的夾克、外套等衣服,容易將髖骨部分判斷在同一側,造成扭曲的衣服形狀。
經過觀察,人物向右轉身(以人物面對方向為基準)髖骨座標容易集中在右側,人物向左轉身,髖骨座標容易集中在左側。因此我以雙肩座標減去(左髖骨+右髖骨座標),取距離較近者作為基準點,以此節第二部分提出之平行線方法,加以延伸,便可修正關節點檢測錯誤之問題。
4. 錯誤檢測資料
實驗過程中,發現了幾件特例會產生錯誤檢測資料,因此對程式進行了條件過濾,以防止此類特殊檢測資料造成程式運行錯誤。由圖6(左)可以看到多人靠近容易將全部人的關節連在一起,形成肩寬特寬的異常情形;圖6(中)可以看出側面容易判斷在外套其中一側,圖6(右)可以看出彎腰動作容易造成關節的連結錯誤。

4.4合成
在合成的部分,首先要先確定背景圖大小與分離出的前景大小,確保前景大小不會超出背景圖,如果超過,則需要調整大小到背景圖大小範圍內。對於前景合成到背景處,我一律採用水平置中,垂直置下,使圖片畫面較為合諧。
處理完前景圖後,衣服的合成也是如同前景圖的判斷,因為衣服是根據前景圖大小調整過的,因此在這一步也需要將衣服與調整後的前景大小一同調整。人物在照片中,不一定是全身入鏡,有可能只照半身,也可能是被障礙物遮擋,因此在這一步驟中,也需要將衣服依據人物在鏡頭中出現的比例貼合,避免衣服超出人物形成異常畫面。
多人的部分,為了避免遮擋,因此在4.1節進行了重疊判斷,在此節,依據4.1節的重疊判斷,對每一個人次依序進行前景合成與衣服合成,前景合成與衣服合成皆完成後,才對下一人次進行合成,如此就可避免衣服遮蓋住人物。
5.呈現結果
本研究結合GrabCut的前後景分離技術以及YOLO篩選人體的技術,在前後景分離方面,達到了速度快,效果佳的成果,同時,利用OpenPose定位人體關節資訊,成功轉換微側身與站姿不同所造成的偏差。在多人方面,本研究也成功利用4.1節的重疊判斷交換圖層相疊順序,成功區分出前後人物,並成功套上衣服。
以下圖8為本研究之單人成果,圖7(左)為原圖,具有簡單背景;圖7(中)是經過前後景分離後的前景結合使用者選擇之新背景,可以看出經過YOLO初步製作mask不僅僅在時間上取得優勢,在分離上也能取得不錯的結果;圖7(右)則是將處理過後的衣服加入新背景中,呈現最後結果。

圖 7 (左)單人原圖[15],(中)前景結合新背景,(右)加入衣服,背景[20]
圖8為本研究之多人成果,圖8(左)為原圖,具有複雜背景;圖8(右)為加入衣服後結果,可以看出分離後的成果不錯,但在衣服疊圖部分,因為偵測到左邊人物右肩跟右邊人物左肩座標上下重疊了,同時左邊人物偵測關節只偵測到肩膀部分,因此依據4.1節的重疊判斷,用肩膀決定他們的上下順序,因此呈現左邊人物在前的畫面。

圖 8 (左)多人原圖[15],(右)加入衣服
6.結論與未來方向
在前後景分離的部分,結合了GrabCut與YOLO節省時間的效果相當明顯,尤其人物比例佔圖片越小,YOLO所起到的功效越大。
而在衣服做透視變換的部分,對於轉身角度越大效果越不明顯,細思原因應是缺乏光源變化導致變形卻看不出深度。
單人實現本研究所有功能的部分已能達到相當不錯的成果,惟多人在前後景分離的部分以及關節點判斷的部分都達不到較好的成果,以致於最後合成成果不佳
未來嘗試利用Poisson image editing[21]去模擬原有衣服的風格,依據論文所提,該方法會去計算合成位置的梯度及散度,模擬合成位置的變化,因此能讓合成圖片看起來更真實。利用此方法,或許能避免計算光源折射、反射角度所造成耗時長的問題,同時使衣服也能具有陰影變化,看起來更有真實感。
多人呈現不佳則暫時沒有好的解決方式,因多人在前後景分離時,會被距離過近的人影響,造成部分部位消失,或是多出部分背景。