壹、工作內容
一、工作詳述
我們所工作的部門是,歷史語言研究所中的數位文化中心。剛到數位文化中心後,由一位負責數位文化中心技術組的主管—王祥安博士,向我們簡單介紹了數位文化中心,並向我們說明上屆實習的學長姐工作,讓我們選擇有興趣的題目接手、或是其他和中心業務有關的題目。 主管給我們的方向主要分為,網頁開發、社群網路分析、文字探勘及影像處理。也給我們約莫一星期的時間思考自己有興趣的項目。
暑假開始,我將文字探勘的工作交接給新來的同學後,開始做與網路、系統相關的工作。
1. 文字探勘
練習
我選擇題目是文字探勘,在確定題目之後,接下來就是學習之後要用到的技術和工具,主要是Java和Solr。 主管給我一本Java的書,要我先熟悉Java的基本語法,並要我去看Solr的官方文件,先學習這兩個技術,以及一個練習題,要我從這個練習開始,熟悉如何使用Java及Solr。而這個練習是要將一些專家和學者的註解、眉批、頁碼等xml的標籤,還原到Solr的查詢到的文章段落中。

上圖為Solr的查詢結果,目標是要將page、qn欄位中的xml標籤,還原到content中原本的位置。

完成練習結果,成功將page、qn等xml標籤,還原到content中原本的位置。
文對文比對功能
在練習完成之後,我也對Java稍微比較熟悉了,主管交代給我的工作內容是, 開發數位人文研究平台網站上的文對文比對的功能。開始前,第一件事就是要將開發環境架設好, 用到的工具包括Tomcat、MySQL、Solr,也因為這是一個許多人合作的專案,所有也會用到Git。
http://dh.ascdc.sinica.edu.tw/ - 數位人文研究平台
數位人文研究平台是由中央研究院數位文化中心(ASCDC)根據人文研究的需求,發展協助學者提升研究質量的數位化工具與平台。數位人文研究平台提供雲端服務,研究者不需擁有強大的運算與儲存設備,只需透過網路即可使用。可提供個人使用,也具有多人協同研究機制,可共享研究資源。
數位人文研究平台,主要由我們數位文化中心開發,因此也有幾位實習的資工資管學長以及技術組內的同仁在開發,而我負責的是文對文比對功能,用於讓與用者能由輸入的文字段落,與資料庫中的文章作比對,找到相似的文章段落。
原本數位人文研究平台上,已經有文對文的相似度比對功能了,但主管說舊版的功能效果並不好,因此需要重新改寫。我主要用的相似度判斷方法為,兩段文字中,相同字的所佔的比例,若是高於門檻值,則視為相似的段落。除了找出相似的段落外,還要將段落中相似的句子標記起來。主管也告訴我可以用一個LCS(longest common sequence)最長公共子序列的演算法,用它來找到兩段文字中,相同字所在的位置的位置。
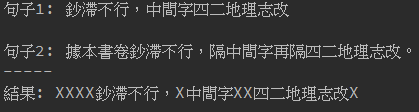
運用LCS最長公共子序列演算法,找出兩段文字中,相似的部分。
一開始完成的版本,我的作法是,用一個段落去把比對的目標書中,所有段落都比對過一次的方式,找到相似的段落(例如:我想要拿n個段落,與我的資料庫中的文章找出相似的段落。假設資料庫中有m個段落,那總共比對的是次數就是(n * m)次),但是搜尋速度太慢。
主管告訴我,可以用一個TF-IDF(Term Frequency - Inverse Document Frequency)的計算詞頻的演算法,幫你找一段文字中重要的關鍵段詞,再用這些關鍵詞作為條件向Solr下查詢,再用查詢的結果作比對就好,這樣可以減少需要比對的次數(減少m的數量)。
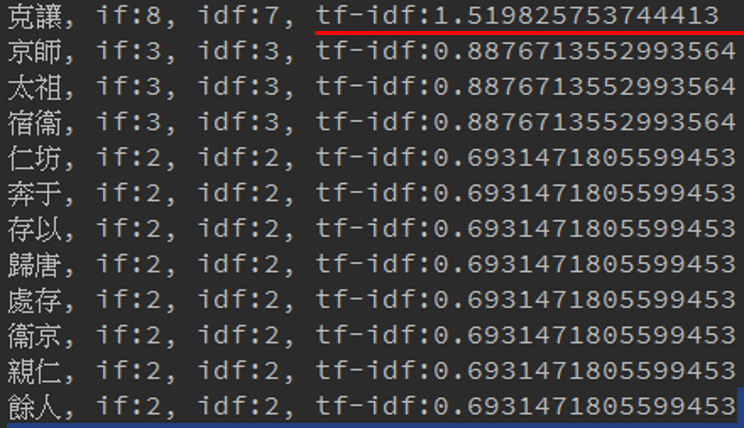
利用TF-IDF這個詞頻演算法,找到一段文字中重要的詞,再用這些關鍵詞組成Solr的查詢語法,向Solr下查詢,再用查詢的結果,與原文本作比對,藉此加快查詢速度。
再經過主管建議的方法修改後,查詢的速度已經有顯著提升。
接下來就是如何把結果呈現在網頁上,也就是網頁前後端的串接,網頁後端也是用Java作開發,也因為自己之前有碰過php,用Java開發網頁時發現,其實兩者的概念是差不多的,因此也沒有遇到較大困難。
除了網頁呈現的部分,主管也會常常提出一些修改建議,例如:在比對相似度的方法,希望能考量到相同文字的密集程度。希望我們可以嘗試看看,把這個想法實作出來,比較看看效果如何。
因為我們所開發的功能是要真正上線,讓使用者去使用的,因此經常需要和主管討論,一些需要改善或修改的部分、增加新需求,還有例外情況的處理。過程中經常會需要去嘗試各種不同的比對方法,實驗看看能不能提升正確率,主管也給我們很大的彈性,並不會要求我們在期限內一定要完成,反倒是希望我們花多一點時間去交叉驗證,或是更好的解決方法。
2. Kubernetes 建置
暑假開始,文字探勘的工作完成到一段落後,工作內容開始以系統維運為主。 我們數位文化中心負責系統運維的人員並不多,在人力資源有限的情況下,我們採用容器來管理的伺服器平台,簡化系統的部署與維護成本。當時我們中心所用的是以Rancher1.x架設的容器管理系統,因舊版的Rancher將無法兼容新的版本,因此我開始研究如何建置以Kubernetes為基礎的容器平台。
我們使用Rancher管理Kubernetes,主要由以下三者組成:
Docker Container : 容器是新世代雲端虛擬化技術,Docker屬於Container的一種 (其他容器還有 Rocket Container, LXC),一般只用於單機使用。
Kubernetes : Container的叢集管理工具,可以管理各種 Container 叢集。 Kubernetes叢集使用的一個以上的實體或虛擬主機的集合,提供給Kubernetes使用執行相關應用程式,其他競爭者有 Mesos, docker swarm。
Rancher : 開源的container管理介面,方便管理者管理監控。2.0版開始僅支援Kubernetes。
因舊版的Rancher將無法兼容新的版本,因此我開始研究如何建置以Kubernetes為基礎的容器平台,並用串接新版的Rancher做管理。
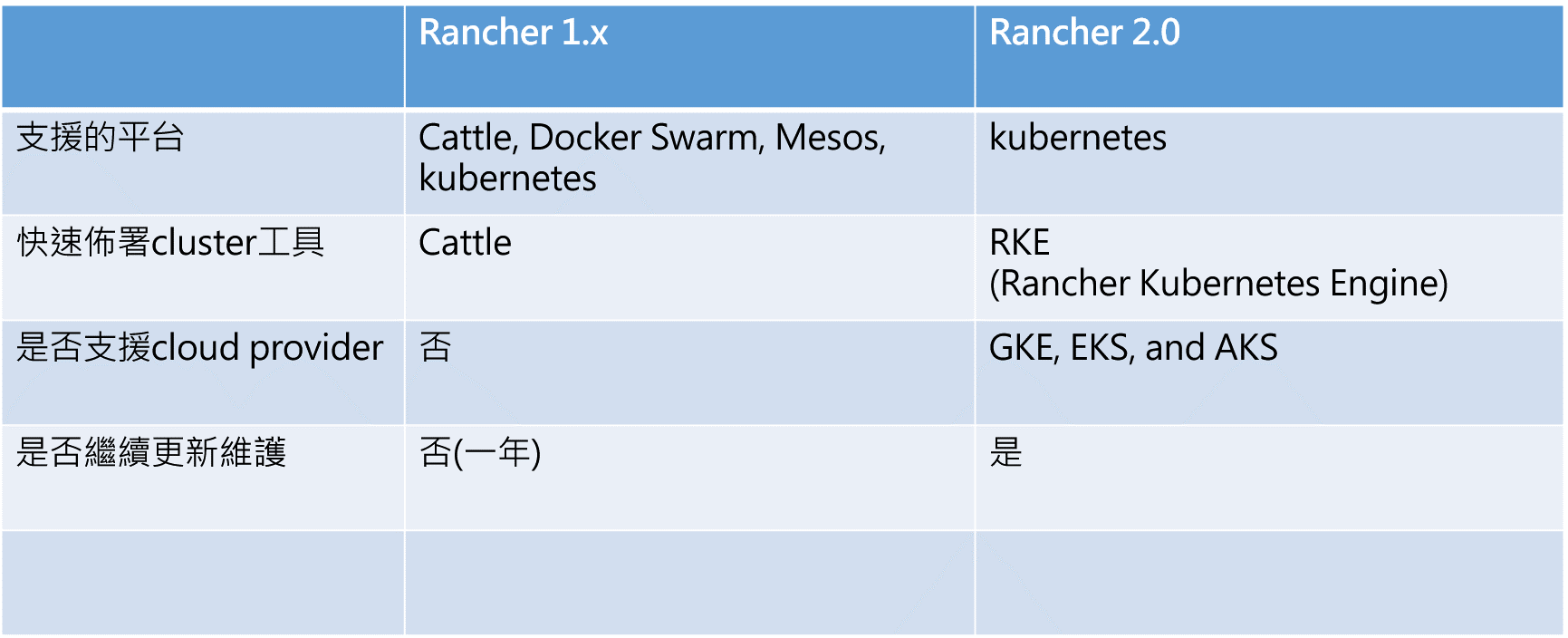
Rancher 新舊版本比較
一開始,主管給了我五台虛擬機,安裝Kubernetes叢集,並研究各個元件的功能、用途。
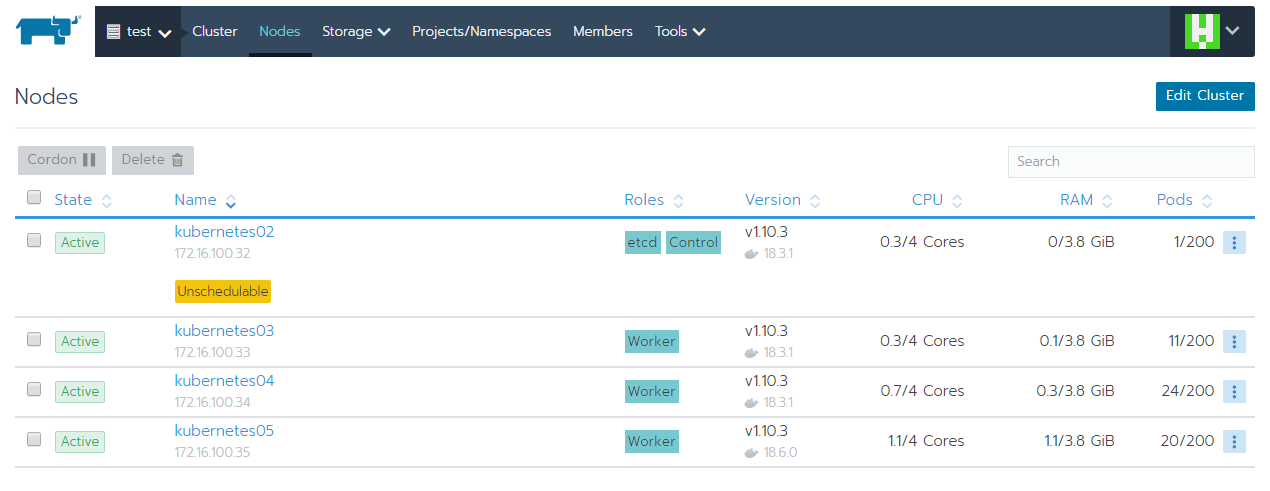
一台虛擬機安裝Rancher,其餘四台組成Kubernetes cluster
Kubernetes cluster是使用的一個以上的實體或虛擬主機的集合,提供給Kubernetes使用執行相關應用程式。cluster中的節點主機分為三種腳色,分別是Masters, etcd, Node:
Masters是Kubernetes中最重要的腳色,提供API Server、叢集資源排程、應用部署管理等功能。
Etcd是一款利用raft一致性算法來實現的分散式資料庫,用於保存cluster所有的網絡配置和元件的狀態訊息。
Node是執行Kubernetes的實體或虛擬的主機,屬於Cluster的一部份,上面可以執行與排程Pod。
除了安裝之外,主管要我研究各項元件,其功能、用途。
Pod: Kubernetes 上會運行很多個不同種類型的應用服務(applications),而一個 Pod 在Kubernetes世界中就相當於一個application;一個 Pod 裡面可以包含一個或多個 Docker Container;在同一個 Pod 裡面的 containers,可以用 local port numbers 來互相溝通。
Deployment: 管理多個Pod,除了部署一個應用服務,提供平行擴展應用服務的能力,提高服務的負載量,也提供版本控制,升級降級的功能,最強大的是他能在正常運作中更新應用程式,使用者不會感覺到服務被中斷;有任何錯誤時或關閉時能自動重新創建一個Pod。
Service : Pod 前面再接一層橋樑,透過這個 NodePort, ClusterIP訪問到 Kubernetes Cluster 內正在運行中的 Pods,並確保每次存取應用程式服務時,都能連結到正在運行的Pod。
Label: 簡單來說,Labels就是一對具有辨識度的key/value 當 Pod 數量越來越多時,管理的維度也會逐漸複雜,譬如如何將 Pod 在不同地區上部署,不同層級的 Pod 如何分開管理,如何決定哪個類型的 Pod,部署在相對應的 Node 上,都是我們在實際場景上需要考量的部分。而 Kubernetes 提供了我們 Labels 這個元件,讓我們能對每個不同屬性的 Pod 都能貼上屬於他們自己的標籤、且將有不同種類的標籤 Pod 做分群管理。
Annotations: 沒有識別用途的標籤。我們可以在Pod的 Annotations 紀錄該 Pod的發行時間,發行版本,聯絡人email等。Annotations 主要是方便開發者、以及系統管理者管理上的方便,不會直接被 Kubernetes使用。
Volume: 可以把Volumes當成是 Kubernetes Cluster 中專們用來儲存資料的地方。不但能將 container 的資料儲存下來,也可以透過掛載(mounting)的方式,供許多個 Pods 同時存取。
因為container 儲存的資料會隨著 container 的生命週期消失而消失,而無法被保存下來。使用Volume讓這個 Pod 中的 container 即便因為某些因素而 crash ,資料仍可完整的被保存下來,讓新產生的 container 能延續使用。
Secret: 協助開發者將一些敏感資訊,像是資料庫帳密、訪問其他台 server 的 Access Token 、SSH Key,以base64編碼,用非明碼的方式(opaque) 存放在 Kubernetes 中,可以當成環境變數(environment variables) 使用,或是掛載(mount) 在 Pod 某個檔案路徑底下使用。
ConfigMap: 提供一個 Configuration 可以統一存放的地方,也提供一個方法讓開發者可以動態且代碼化的方式為每個應用服務配置其相對應的 Configuration,這樣設計的好處是,無需修改 container 程式碼,可以替換不同環境的 Config,開發過程中,常因應不同的環境需配置不同的 configuration,像是 staging 與 production 存取的資料庫位址不一致等等。無需修改程式碼的特點,可以幫助我們更快部署到各個不同的環境中。
Ingress: 使 Node 對外開放的 port 統一,結合 Ingress Controller 更能在 Kubernetes Cluster 中實現負載平衡 的功能。

當多個 Service 同時運行時,Node 都需要有相對應的 port number 去對應相每個 Service 的 port number

若是使用 Ingress ,我們只需開放一個對外的 port number,Ingress 可以在設定檔中設置不同的路徑,決定要將使用者的請求傳送到哪個 Service 物件
這樣的設計,除了讓運維者無需維護多個 port 或頻繁更改防火牆(firewall)外,可以自設條件的功能也使得請求的導向更加彈性。
Cronjob: 有時我們會需要有個週期性運行的服務,像是每天早上出昨天網站流量的報表,或是每隔一段時間去訪問某個 API 取得目前該應用服務的最新資訊。像這樣每小時、每日、每週、每月每隔一段固定時間要做的工作,我們會丟到 Linux 的 crontab,而 Kubernetes 也提供了Cronjob 元件幫我們實現排程服務。
Namespace: 當 Kubernetes 提供給越來越多人使用時,Namespace讓我們能根據專案不同、執行團隊不同,或是商業考量,將原本擁有實體資源的單一 Kubernetes Cluster ,劃分成幾個不同的抽象的 Cluster (virtual cluster)。
這對我們中心來說是相當重要的一項功能,因為我們中心同時有許多專案同時會使用這個平台,而如何劃分資源給不同專案使用,也是一大問題。
以上元件外,也有許多細節上的調整,透過這些Kubernetes提供的功能,能減輕系統維運人員的管理負擔。
Healthcheck: Health Checks 協助我們去偵測 Pod 中的 containers 是否都還正常運作,確保服務本身也能正常運行。有些時候,雖然 Pod 還在運行,但在 Pod 中的 web app container 可能因為某些原因已經停止運作,或是資源被其他 containers 佔用,導致我們送去的 request 無法正常回應,這時利用Health Checks的功能,Kubernetes會自動替我們做好檢測服務是否正常的工作,減輕系統維運人員的管理負擔。
Autoscaling: 在許多實際場景中,應用服務常常需因應不同流量而配置不同的資源。好比:原本的應用服務可能每天都只有 10 人使用,我們只需要架設一台小 server 即可應付這些流量;當有天應用服務因為某些因素使用人數上升到 10 萬人,可能我們原有的資源不足以回應這些流量,導致使用者無法連上該應用服務。 Kubernetes會依據目前的資源使用率,決定是否自動調整資源來回應這些流量(像是加開 server)來應付流量。
除了研究各個元件的功能,因為之後要將container自舊的系統移植到新的Kubernetes平台上,我也研究了如何解決一些在新舊系統上,與新系統上設計原理不同而造成的問題,例如新舊系統在Volume掛載方式上的機制不同。
舊的系統中:volume掛載到container中,會將container及volume中的資料同步,新的系統(Kubernetes)中:volume掛載到container中會以volume的狀態為主。 因為這樣的差異造成,有些資料存在container中,但想要把它取出來,而掛上volume後,卻被覆蓋掉了。因此主管也要我想辦法解決他。而我想到的解決方法是,開兩個container掛上同一個共用的volume,將A要保留的資料複製到共同的volume下,再把這個volume掛載到B要的資料夾下。如此解決了這個問題
除了學習各項元件的用法,因應主管的需求,建置了一套監控服務在Kubernetes上。 對於維運團隊而言,如何監控應用服務在 Server 上的資源使用是個很重要的事情,透過監控、可以偵測目前服務是否發生異常之外,也可以透過過去監控的資料對服務做最佳化。
而我使用的監控服務由Prometheus, Grafana, AlertManager三者組成:
運作流程:
1. Prometheus Server 定期向Kubernetes的Exporters 中拉取資源使用狀態
2. Prometheus Server 在 Local 儲存收集到的 Metrics,並運行已定義好的規則(alert.rules),當符合的情況發生時(例如:CPU使用率超果80%),向AlertManager 發送警報
3. AlertManager依據設定的通知方式,向管理者的Email或是slack送出通知
4. Grafana透過Prometheus提供的查詢語法,設定出符合需求的圖表(Dashboard)
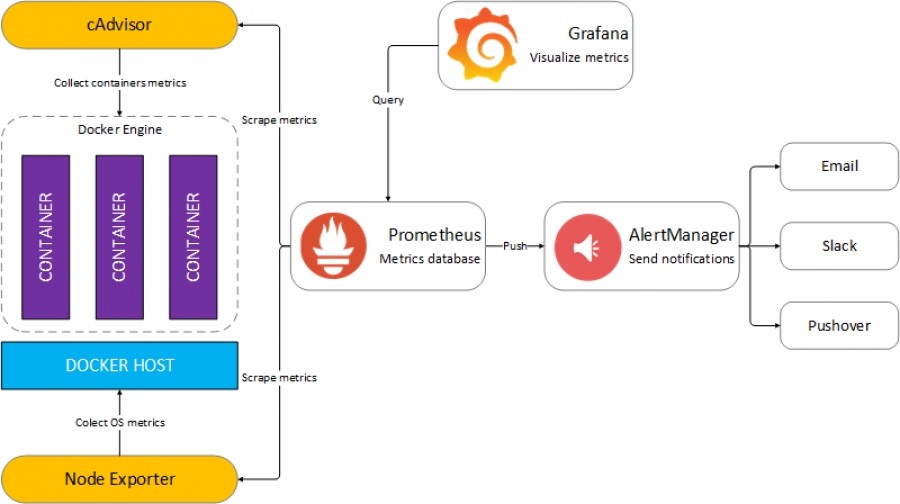
運作流程圖
Prometheus: Prometheus負責蒐集Kubernetes的系統資源使用資訊。它是一套開放式原始碼的系統監控警報框架與TSDB(Time Series Database)。時間序列資料透過 Key-value 來區分,且可以設定任意的多維標籤,並提供靈活的查詢語言(PromQL),可進行加減乘除等,基於 HTTP 的 Pull 方式收集時序資料,支援多種視覺化儀表板呈現,如 Grafana。
Grafana: 一個可將這些數據視覺化的平台(Dashboard),透過Prometheus提供的查詢語言(PromQL) ,將搜集到的資料變成圖表呈現出來。
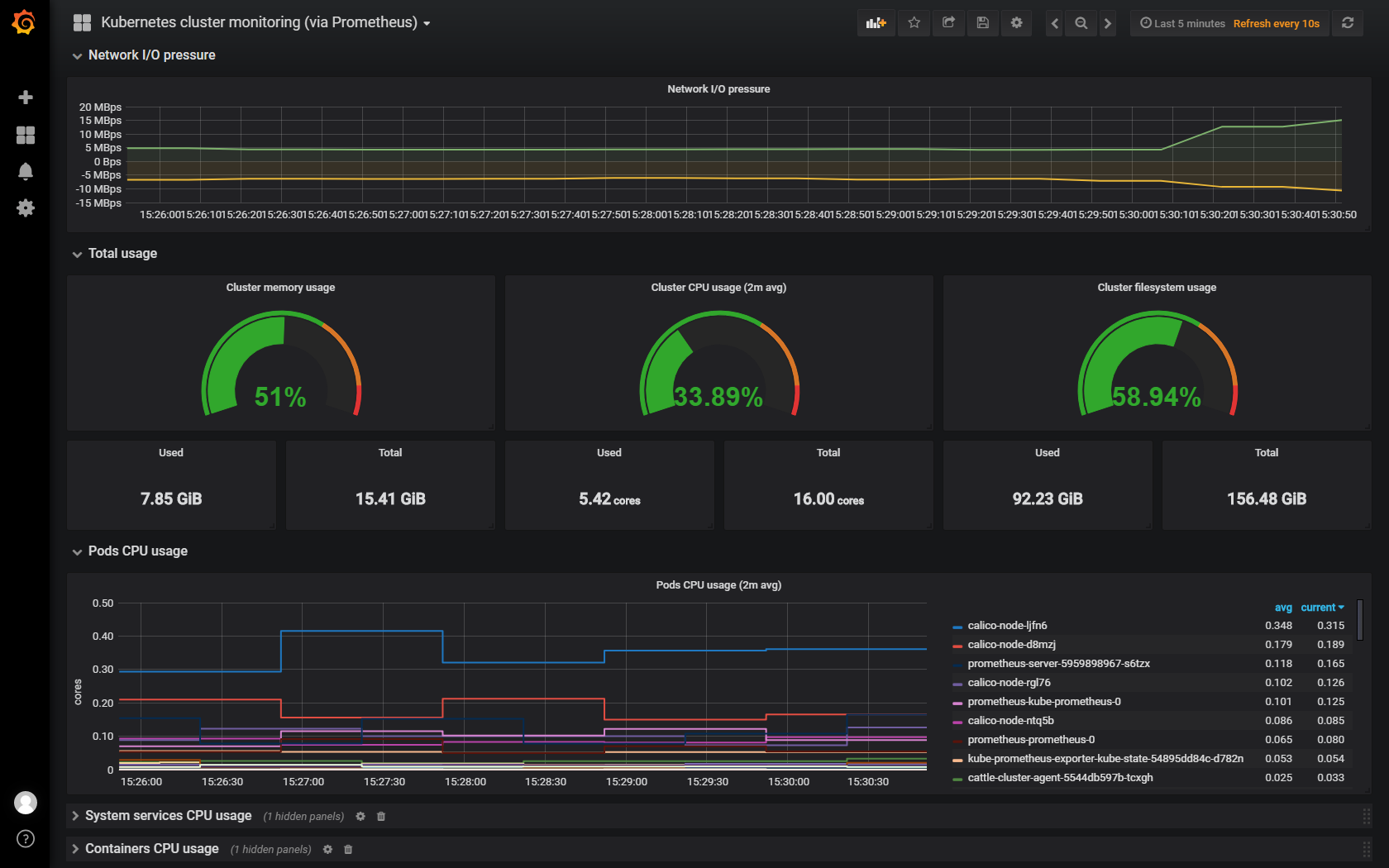
Grafana介面
AlertManager: 接收來至 Prometheus Server 的 Alert event,並依據定義的 Notification 組態發送警報,像是E-mail、slack 與 Webhook 等等
接者主管要我研究如何在ESXi上大量部署Kubernetes。除了Rancher本身提供的GUI介面,可以直接設定的方式外,也自己嘗試使用ansible以及rke (自動化腳本工具)完成大量部署的工作。
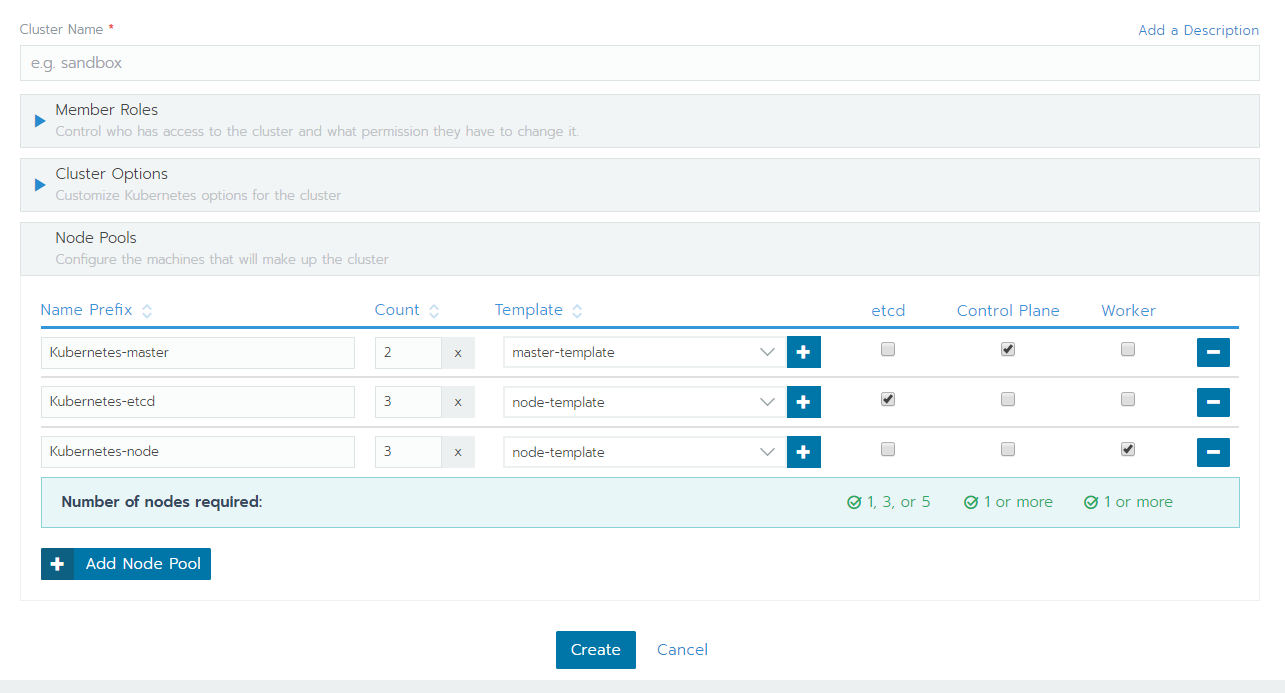
用Rancher大量部署Kubernetes
最後,主管要求我把學習的結果,記錄下來,製作成使用手冊,分成給使用者看的使用說明,以及給管理人員看的架設教學。
使用手冊,分成給使用者看的使用說明,以及給管理人員看的架設教學
3. 封包轉送工具開發
Kubernetes架設及使用研究告一段落後,目前正在使用DPDK開發網路流量分流的工具。 因遇到辦公室路由器,同時上網人數過多,開始出現當機等網路不穩定現象,欲解決路由器超載之問題,因此利用DPDK這個開發工具包,開發一個網路封包的轉送工具,將網路流量分流至多台NAT伺服器,嘗試解決單一路由器效能不足的問題。
二、實習期間完成的進度
1.文對文比對功能
以下為我負責完成的功能示意圖。
主要分為兩種比對方法, 一是選擇資料庫中已有的文章段落,來與資料庫中的目標書作比對。 二是由使用者自行輸入文章段落,來與資料庫中的書作相似度比對。
功能一:
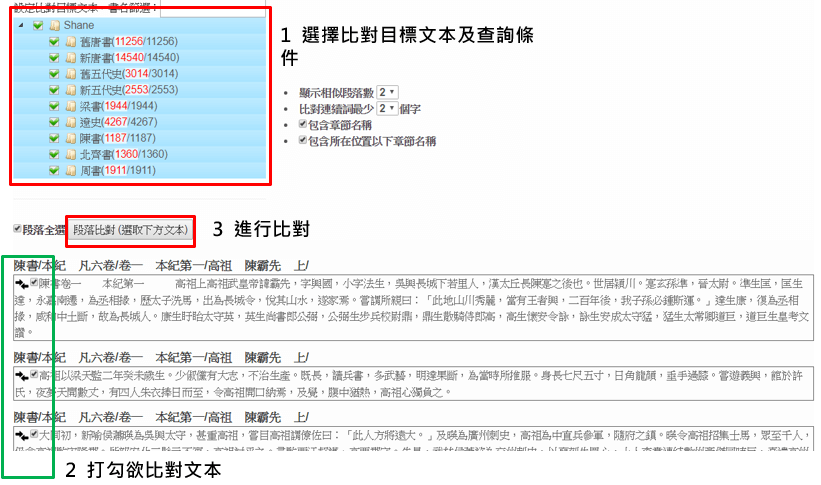
選擇欲比對文本、查詢條件和目標書,進行相似度比對。

查詢結果
功能二:
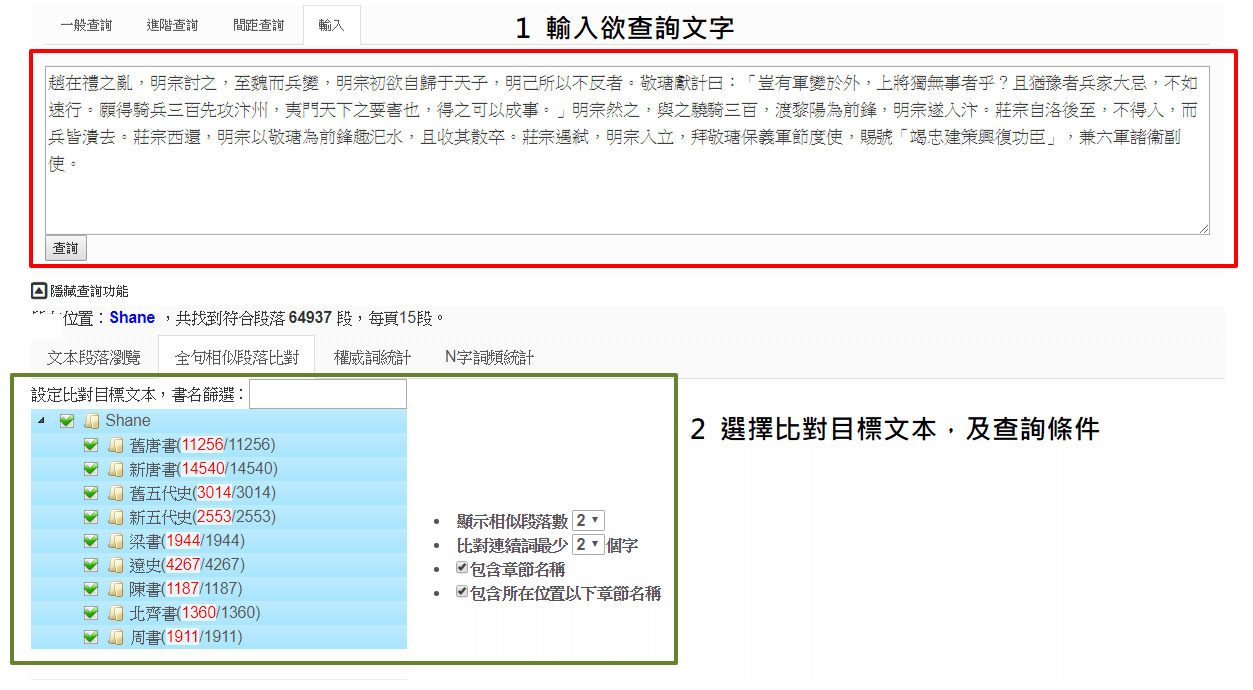
由使用者輸入欲比對文本、選擇查詢條件和目標書,進行相似度比對。

查詢結果, 並讓使用者可以再次輸入文章作比對
2. Kubernetes 使用手冊
主管要求我把學習的結果,記錄下來,製作成使用手冊,分成給使用者看的使用說明,以及給管理人員看的架設教學。
使用者版本的使用手冊,包含了如何使用Rancher開啟Container,和一些基礎的概念,讓使用者可以快速上手。

管理者版本的使用手冊,包含了如何Rancher的安裝、部署,以及一些做設定,把我所學到的各項功能,設定方法記錄下來。
三、工作當中扮演的角色
在工作中主要扮演的角色為,程式設計的工作,我們每週需要和組長報告我們的工作進度,平常也要與帶領我們的主管討論工作細項、需要修改的地方,或是一些新的方法需要我們去做實驗,並在報告時提出我們實驗的結果。
幫助主管研究一些新的技術,解決遇到的問題,雖然不會參與到正式使用環境的架設,但是學習的過程中,這裡有很多的設備資源,是在學校沒有機會碰到的,是很不錯的機會。
貳、學習
一、 Java
在實習期間,由於主管們大部分都是使用java進行開發,為求程式能共兼容,因此做為我們工作中主要使用的程式語言。在經過一段時間的使用後發現,其實java的網路資源其實很多,當遇到問題時,很容易就可以在網路上找到解決方法。對不熟的人而言相對容易找到資源,且功能完善,也不需要小心翼翼的處理指標問題,我覺得java是款非常適合做為大型程式開發的程式語言,且用途也很廣泛。
二、 Solr
Solr主要被用來儲存文本的資料,並用Java透過API來與Solr做溝通。之前只有聽過Solr這樣的全文檢索工具,來到這裡實習後,才第一次有機會實務上使用到這樣工具。 我覺得Solr很像是NoSQL的一種,大多是用來儲存沒有固定結構、且不須經常修改的資料,與學校所教的MSSQL、MySQL等關聯式資料庫不太相同。
三、 LCS (longest common sequence) 演算法
最長公共子序列(LCS)是一個經典的計算機科學問題,用途在一個序列集合中(通常為兩個序列)用來查找所有序列中最長子序列的問題,就是「最長共同子序列」。LCS也應用在許多地方,像是Git的diff功能也有應用到LCS演算法。 而我們把LCS應用在兩段文字中,找到相同字的部分。
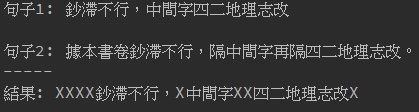
運用LCS最長公共子序列演算法,找出兩段文字中,相似的部分。
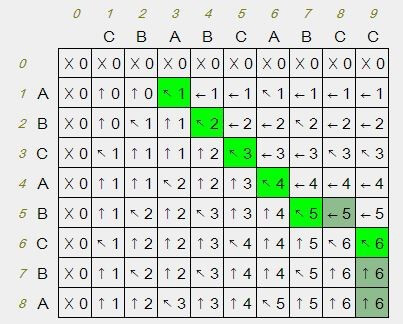
在一堆字裡面,相似子字串有相同左上的箭頭連在,一起最長的就是最長公共子序列。
四、 tf-idf(term frequency–inverse document frequency)
tf-idf是一種用於資訊檢索與文字挖掘的常用加權技術。tf-idf是一種統計方法,用以評估一字詞對於一個檔案集或一個語料庫中的其中一份檔案的重要程度。字詞的重要性隨著它在檔案中出現的次數成正比增加,但同時會隨著它在語料庫中出現的頻率成反比下降。
我用了tf-idf這個演算法,找到一段文字中的關鍵詞,並減少相似度比對時的比對文章次數,進加速查詢的速度。
主管也和我簡單解釋tf-idf的原理,tf-idf用於評估字詞在文章中的重要性,若是出現的次數多,代表它是重要的關鍵詞,但若是這個字詞經常出現在資料庫中的各個文章中,表示這組字詞不足以代表這段文本中的關鍵字。
五、 Git
在工作中,我們也使用Git作為版本控制的工具,每當功能完成到一段落後,我們會將程式碼push到gitlab上的repository,再由主管做整合的工作。
六、 如何做好報告
由於我們每周三都要進行一次進度報告,因此可以藉此磨練報告的技巧,我們對自己這星期做了什麼很清楚,可是要如何講解給其他人聽得懂,卻是一件不容易的事。由於組長及主管們平時都很忙,也有許多自己的事要處理,報告如何做的讓人一目瞭然、講解如何讓人能聽得懂,這都是需要花時間練習的。
六、 Kubernetes
Kubernetes是由Google所開源的一套Container Cluster系統,是目前最受歡迎的容器管理工具,並已逐漸成為主流。可以兼容於docker與rkt等container系統,提供一套跨雲的Container解決方案。透過Kubernetes,讓使用者可以輕鬆建置自己的雲端orchestration,並且可以在公有雲、私有雲以及自建的本地端環境中,而不用擔心被雲服務不同的API所限制。
ubernetes可以說是同容器Docker一起發展起來的,它提供應用部署、輕量級、維護、擴展機制等功能,他建構在容器技術之上
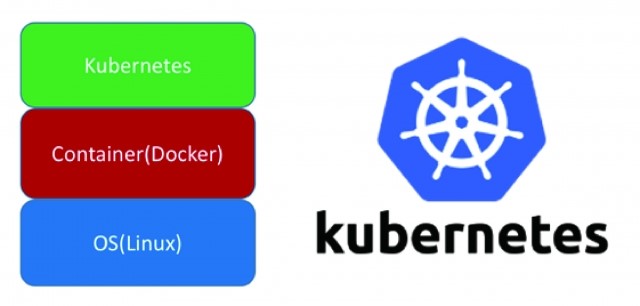
Kubernetes最底層是作業系統Linux,而Docker容器建構在作業系統上,Kubernetes又建構在Docker之上,也因此為這些Docker所起的容器提供管理的功能,就像這些獨立容器個體之中的導航!非常巧的是Kubernetes官方的logo就是船陀,其字本意是古希臘語陀手的意思,我想這大概是命名的由來。Kubernetes也利用Google在容器技術上的實戰經驗,同時吸收Docker社群的最佳實踐,已成為雲端服務的重要陀手!
利用Kubernetes可以方便的管理跨機器執行容器化的應用,主要的功能大概如下:
-
使用容器(例如:Docker)對應用程式包裝、實例化、隔離、運行。
-
以叢集的方式執行、管理本機或是跨機器之間的容器。
-
解決跨機器容器之間的通訊問題
-
Kubernetes的自我修復能力,使得容器叢集總是運行在用戶期望的狀態
七、 網路封包轉送程式
辦公室路由器因同時上網人數過多,開始出現當機等不穩定現象,欲解決路由器超載之問題,學生用C語言搭配DPDK函式庫開發一個網路封包的轉送工具,將網路流量分流至多台NAT伺服器的小工具。 開發過程中,更清楚理解書上的網路理論知識,以撰寫程式的方式將這個過程實作出來,令我對封包傳輸原理更加清楚,更能理解網路再傳輸過程究竟怎麼處理的。
DPDK(Data Plane Development Kit)為Intel開源的專案,這個開發工具是一組針對封包快速處理的函式庫及驅動程式,其目的是讓應用程式不用透過kernel直接處理訊息(message),並且將電腦的實體資源如cpu、ram等跟其它程序進行隔離,因而提高處理速度。
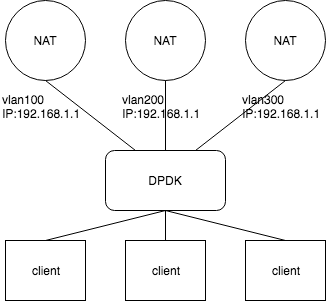
封包轉送工具之架構圖
參、自我評估及心得感想
若以自己這段時間的表現,我給自己的評價是,還算滿意,基本的不遲到、不早退,除非必要也幾乎不會請假,工作方面我也會盡力完成主管交代的工作,也會想怎麼改善細節的部分,盡力把事情做好。在報告的部分,我覺得我可以做得更好,如何表達得讓其他人知道我想說什麼,我覺得這部分是我需要多練習的。
相比於與在學校上課,我覺得實習有更多的實作機會。由於我們數位文化中心的定位是在為保存文化、歷史資料進行創新應用及保存再利用。這裡擁有許多重要的文化資產,而大部分的民眾對這些內容其實相當陌生,要如何讓這些文化資產進入大眾的生活,又或者要提供文化資產,讓專業學者們研究,如何提供好的工具也是我們的目標,因此我們運用科技、電腦技術幫助學者進行研究。而影像辨識、網頁標註、文字探勘都是其中的一環。
到中研院實習我覺得是件幸運的事,暑假前我曾經和主管討論過工作方面的問題,主管也願意幫我調整方向,因此暑假開始我開始做一些自己感興趣的工作,這裡資源很多,如果有問題,其他同事也很願意教你,在暑假期間真的學到了很多。除了工作,在這裡也有寫論文的機會,把做的事情用論文的方式記錄下來,到研討會上分享,主管也會幫我們看過,給我們修改的建議,這對未來想讀研究所也會有很大的幫助。
這次的實習也讓我體會到上班是什麼樣的感覺,由於寒暑假時的上班時間為一到五,一整天坐在電腦前,盯著電腦螢幕,剛開始真的會覺得有點不習慣。在這裡的工作,主管們並對我們並沒有太多的規定,累的時候其實也可以到辦公室面外走一走、或是看看其他同學在什麼事情。但是和在學校上課相比,我會覺得上課其實是相對比較輕鬆的,因為工作還是會比較有進度上的壓力。但也因此有更多的挑戰,也需要更多的耐心去面對並解決遇到的問題。
肆、對系上的建議
第一件事要感謝系上提供這樣的實習機會,讓我們能有機會到外面的公司實習,體驗到從準備履歷、面試到上班的經驗,了解自己缺少什麼樣的職場能力,體會到什麼樣的工作內容、工作環境是自己喜歡的。相信這次的實習經驗,能為我們未來的職涯有很大的幫助。