工作詳述
前言
我在一月二十二號就到數位文化中心報到了,第一週的時候主管介紹了目前數位研究中心正在進行那些專案,並聽取負責 各專案的學長、姊介紹他們正在負責的專案。 我對於網頁的前端及後端開發最感興趣,因此最後我選擇的是雲修學長正在開發的 「網頁註記系統」專案, 而之後就展開了一個半月的交接流程。
交接項目
- Web Annotation
使用PHP的Laravel框架進行開發的圖片註記工具,是一套完整的圖片註記工具,已經有使用在正式版的網頁上。 包含完整的MVC架構因此所有的圖片註記均會被存到資料庫,且有會員管理機制因此需要登入帳號才能進行圖片預覽以及註記,也包含獨立的管理介面甚至可以搜尋註記。

▲上圖為圖片註記工具的介面
- IIIF manifest editor
前端使用React.js來設計頁面並搭配 Leaflet.js 來製作圖片的顯示器,有完整的使用介面可以讓使用者選擇要 看的manifest。除此之外, 也將Web Annotation所開發的annotation.js 移植到這裡的圖片顯示器上,可以進行圖片的註記,但是尚未將註記及manifest的資料存進資料庫保存。
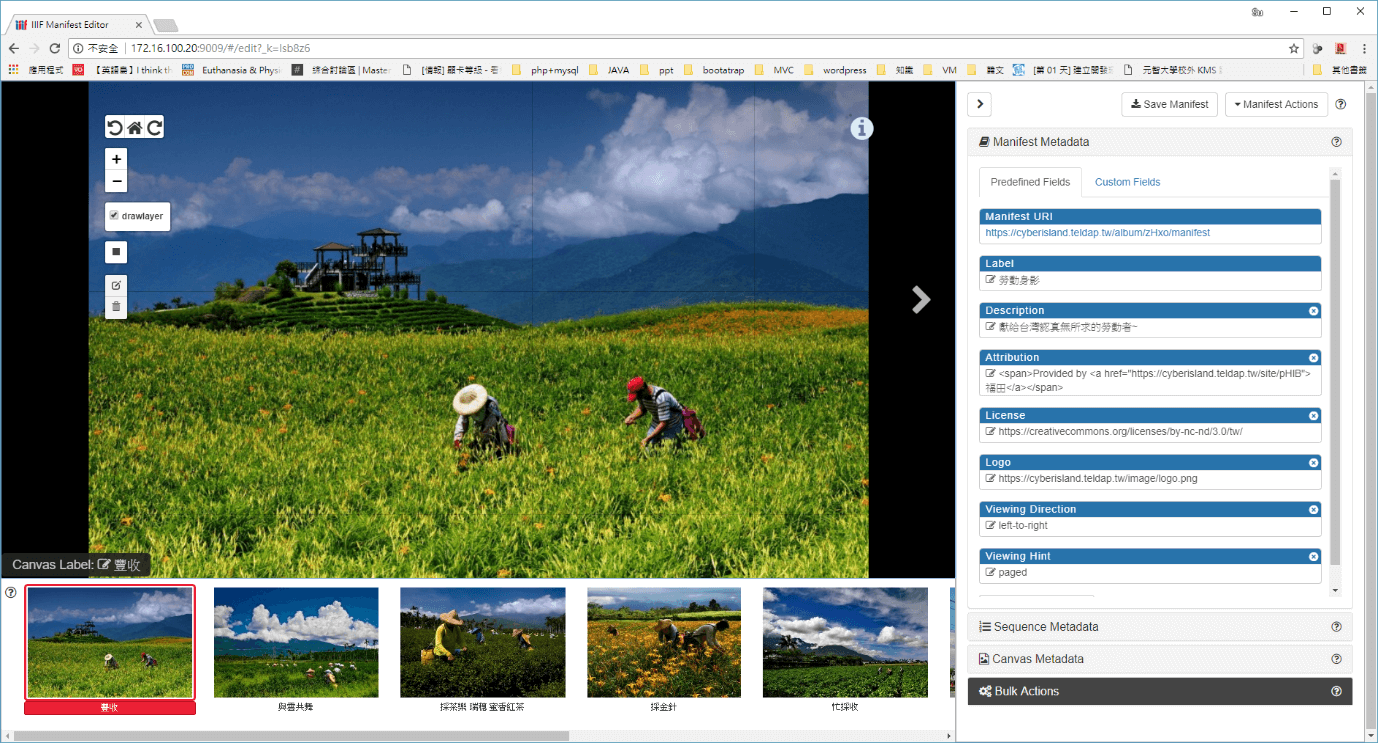
▲上圖為IIIF manifest editor的介面
- 佛教原型系統
學長將中心其他同仁設計的Html介面套上css以及註記的JavaScript來讓網頁能夠呈現圖片、顯示圖片資訊、 旋轉圖片以及進行註記。 這個系統只是原型而已,目前僅有展示系統架構的意義。主要目的為將viewer應用至中心其他專案,讓其他專案藏品的照片也能夠進行註記。此專案目前以有另外的實習生接手改善介面與設計會員管理系統,我將持續提供最新版的viewer給他。
目前最新版的viewer中預計會新增的功能包含了會員管理機制、實作Authentication API和Content Search API,而這些功能現大多已幾乎都完成,僅剩下後來追加的圖片比較功能仍在開發中。
正在進行項目及進度
- IIIF manifest editor的後端
- IIIF manifest parser
- 影像辨識標記系統
由Node.js所進行開發的後端server,為IIIF manifest editor的viewer建立manifest API, annotation API, manifest parser來做資料的儲存和資源的控制。這些後端程式主要使用Express.js來做web API並根據REST的設計風格製作出RESTful API的伺服器。REST設計風格的特點在於資料 由URI指定再搭配http method就可以對資料進行CRUD的RESTful API。 manifest API主要的功能在於將manifest存在資料庫,並可以透過GET取得manifest以及PUT可以進行更新。 annotation API 的主要功能在於操作資料庫來控制註記,讓操作IIIF manifest editor的viewer可以達到儲存註記的新增、更新、刪除、移位。
為了能將圖片註記的功能結合到數位文化中心正在進行的專案上,需要透過 IIIF manifest parser來進行驗證 管理以及與Image Server進行溝通。透過Node.js並依照IIIF Authentication API的規範,實作出可以管理使用者有沒有權限看到圖以及能不能夠對圖片進行註記。
將現有的圖片註記工具延伸開發為能夠產生機器學習資料集並自動訓練模型的圖片標記工具,註記(annotation)與標記(label)有些微差距,註記主要指的是在圖片上以圖層的方式指出位置並以文字加以描述。而標記在這裡指的是在機器學習中,影像辨識需要的訓練集中的資料集(dataset),其裡面主要包含bounding box以座標框出物件。
以下是功能流程圖以功能描述:
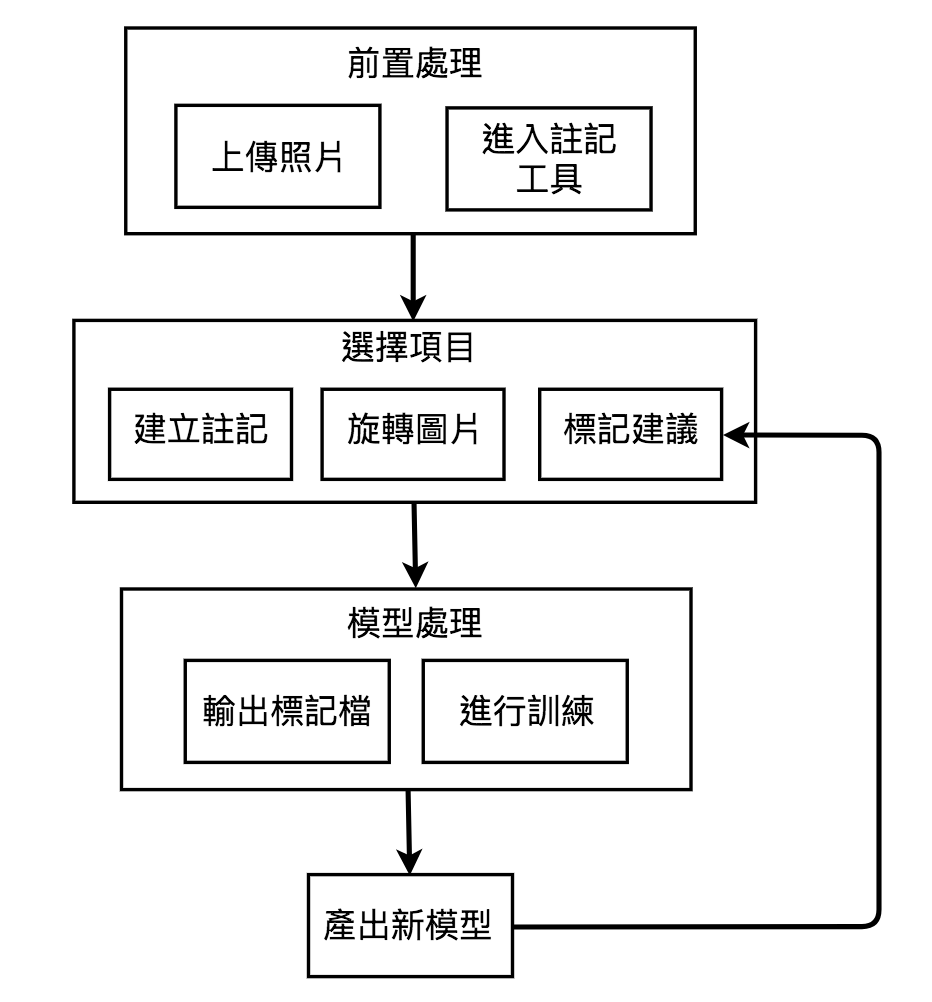
▲上圖為影像辨識標記系統的功能流程圖
上傳照片的介面為採用Github上的開源專案jQuery File Upload, 並搭配自己撰寫的Node.js照片管理伺服器來處理檔案管理。此開源專案是Github上檔案管理類別最多人使用與擁有最多星星,且廣泛支援各式的後端伺服器。在開始使用註記工具前,使用者須先上傳照片,當檔案開始上傳時,便會同步儲存一份至處理影像辨識的伺服器上,省去使用者需手動管理本機端和伺服器端檔案是否一致的困擾。在圖片上傳成功後,便會在上傳介面上提供圖像註記工具的連結,方便使用者快速進行註記。
進入圖片顯示器視窗時,圖片註記工具會根據最新訓練好的模型來進行預測,並將預測的結果以方框的形式呈現在圖片顯示器中。使用者可以依據需求決定要保留所有建議、全部移除或是稍微做修改。
當圖片的註記完成後,按下Export按鈕後才會將方才完成的註記產出成影像辨識所需的label檔案,並同步儲存到處理影像辨識的伺服器上。目前使用的影像辨識框架為keras-yolo2,因此這裡預設產出的label檔案為XML格式,目前也支援產出JSON格式。IIIF APIs會計算從上次訓練後,訓練伺服器上的資料集數量變動。當訓練新增的label檔案數目達到一定後,便會呼叫影像辨識軟體重新訓練模型,新訓練好的模型和舊的皆會分別保留。
For for information, please check the System Design & Demo page.